最近朋友想让我帮忙把抖音的主播都爬出来。网上看了一些教程,大部分都是爬视频的。没有找到现成的爬所有主播的。所以参考了很多教程,自己写了一个专门爬主播数据的爬虫。系统是Windows 10,时间2021年1月12号。用这种方法略做修改基本可以爬取抖音所有数据,有兴趣的欢迎交流。
必备
- MitmProxy:https://mitmproxy.org/
或者在git中安装: pip install mitmproxy(详细见下面配置-》配置python) - 网易MUMU:http://mumu.163.com/
也可以用夜神模拟器,或者直接使用手机,配置上略有不同 - Appium:http://appium.io/
按需下载
- Anaconda:https://www.anaconda.com/
- Git: https://git-scm.com/
- Pycharm:https://www.jetbrains.com/pycharm/
- 我用的Anaconda, 不了解的可以先看下教程 学习Python建议用什么编译器?
- 打开git bash
win+S, 搜索"git bash"


- conda create -n pachong python=3.6 新建虚拟环境pachong,python版本3.6
- conda activate pachong 激活爬虫环境
- pip install mitmproxy 安装 mitmproxy
- mitmweb -p 8888 打开代理,开始检测 -p后是端口号,会打开一个网页,这个网页会监听所有经过8888端口的https请求
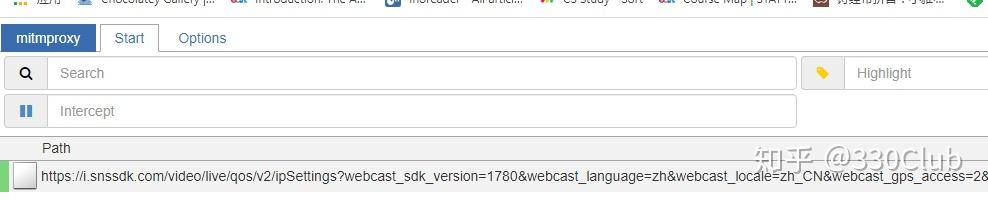
- 打开网易MUMU
- 依次点击 桌面-》系统应用-》设置-》WLAN,长按当前网络,选择”修改网络“-》代理-》手动
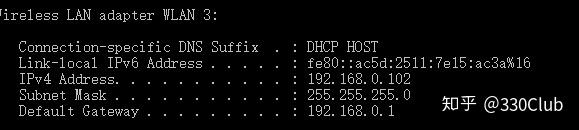
代理服务器主机名:本机IP
打开command命令行工具,输入ipconfig,按回车,IPv4 Address就是本机IP
代理服务器端口:第一步中-p后自己设置的端口,这里是8888
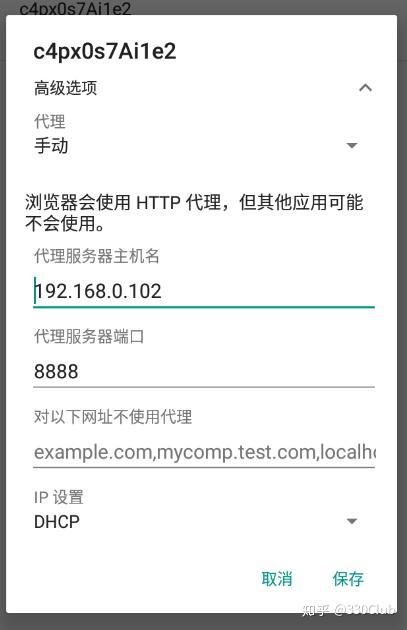
填完后点击保存
- 下载 JDK:https://www.oracle.com/java/technologies/javase-downloads.html
- 下载 nodejs:http://nodejs.cn/download/
- 下载 Android SDK:https://www.androiddevtools.cn/
- 安装完成后,配置环境变量
添加ANDROID_HOME变量,地址填入你安装的目录
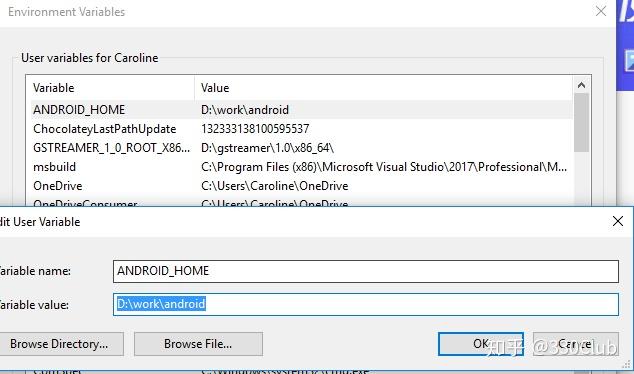
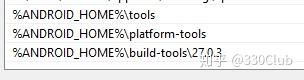
在path中加入下面三个环境变量,主要是为了在command命令行中使用adb
打开新的命令行工具,输入adb,看是否能识别adb命令, 如果不能识别,那么是环境变量配置错误,确保path中ANDROID_HOME下的platform-tools下面有adb.exe

- 在命令行中输入adb devices查看是否连接上网易MUMU,如果没有,在命令行输入 "adb connect 127.0.0.1:7555", 其中7555是网易mumu的端口
- 打开Appium

点击"Edit Configurations"
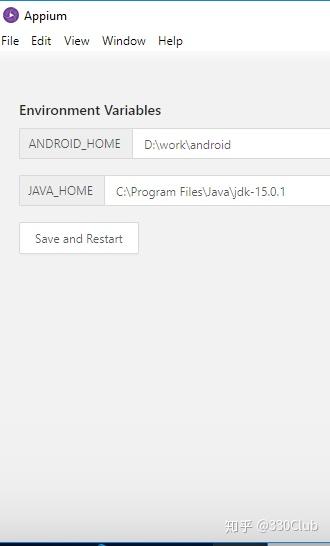
填入Android SDK和JDK的安装目录,然后“Save and Restart”
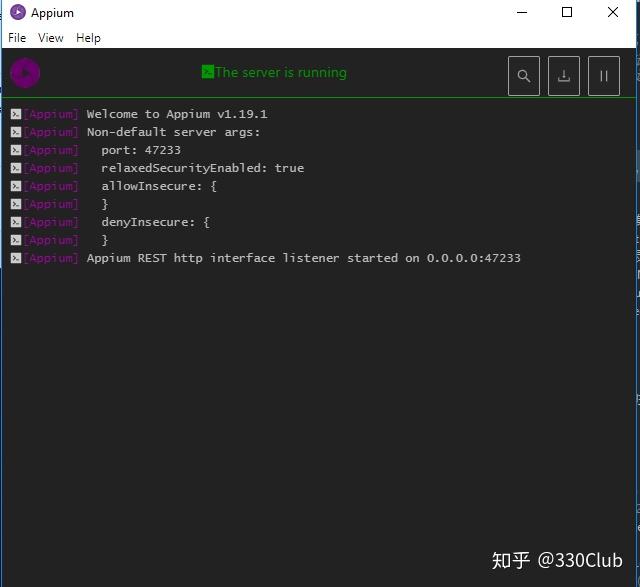
Appium重启后,点击“Start Server v1.19.1”, 如果提示端口被占用,改成其他端口,我使用的是47233
点击右上角的第一个按钮“Start Inspector Session”, 打开新的窗口
在"Desired Capabilities"下面添加配置,然后保存
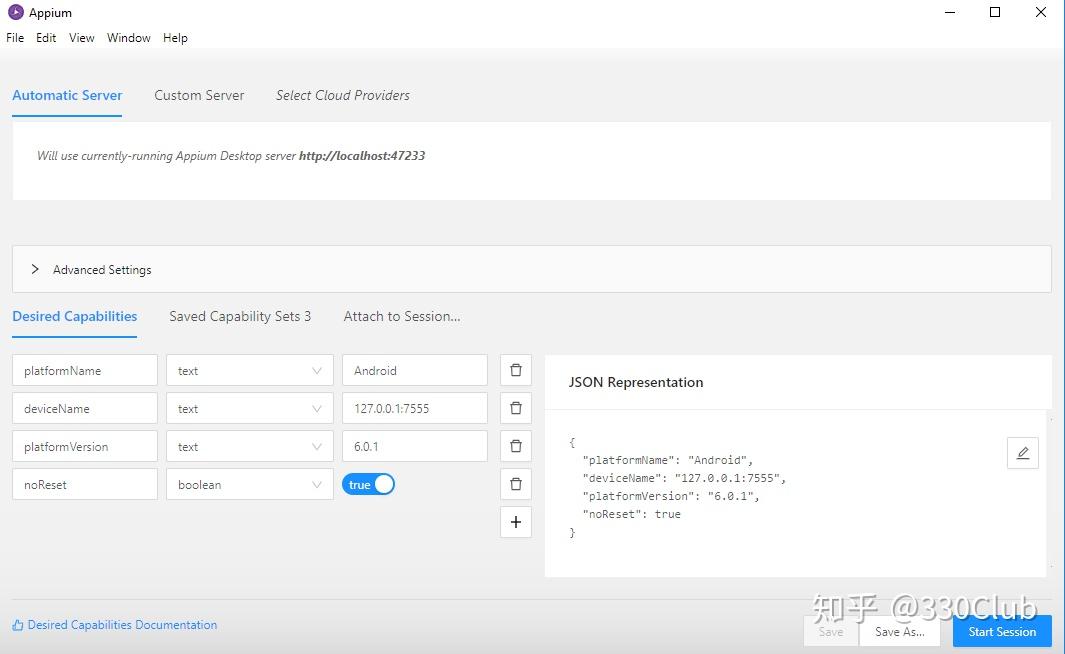
点击“Start Session”
确保mimtproxy开启,git运行“mitmweb -p 8888”,确保网易mumu开启,并且连接成功“adb devices”中能看到。
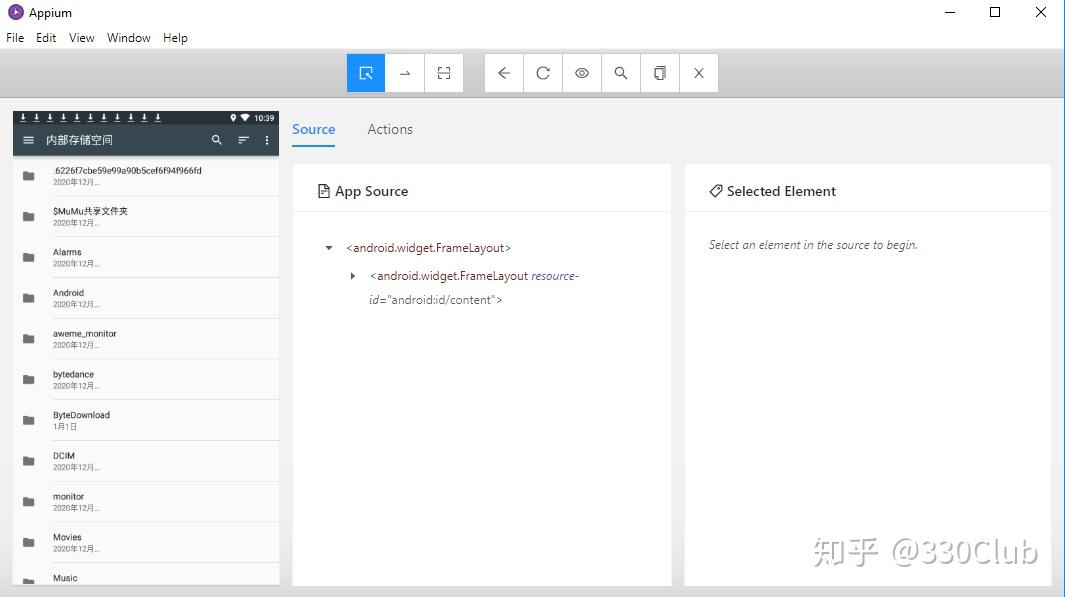
如果提示证书错误,那么需要安装证书,网上安装证书教程如下,但是我一直下载不成功,所以直接下载的windows版证书,双击安装,也能正常使用。
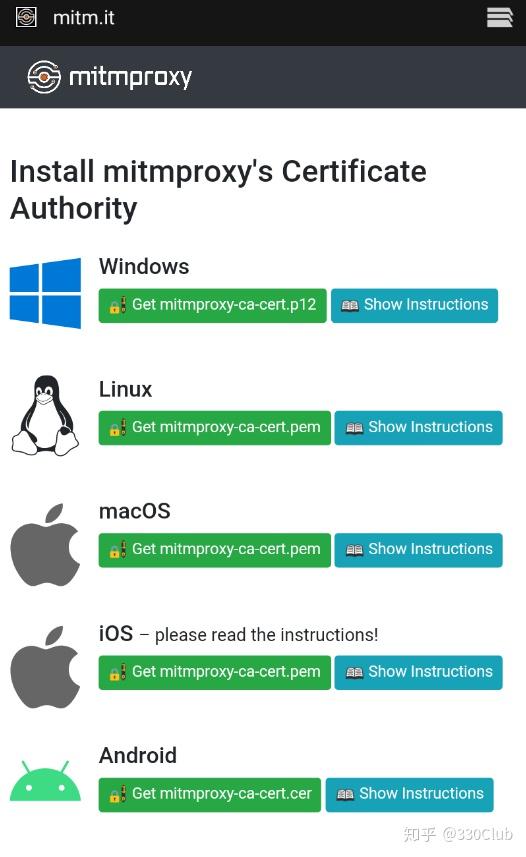
- 安装证书
打开桌面上的浏览器,地址栏输入“mitm.it”
打开桌面上的浏览器,地址栏输入“mitm.it”
- 在网易mumu 中下载抖音
搜索栏,搜索“抖音”
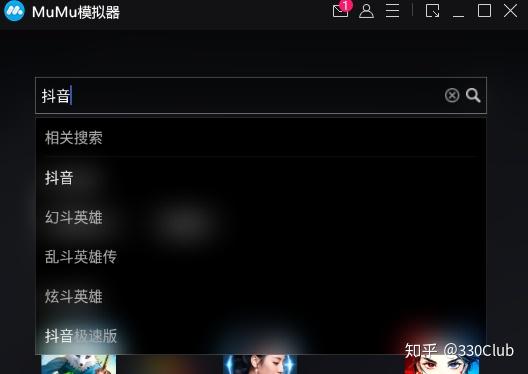
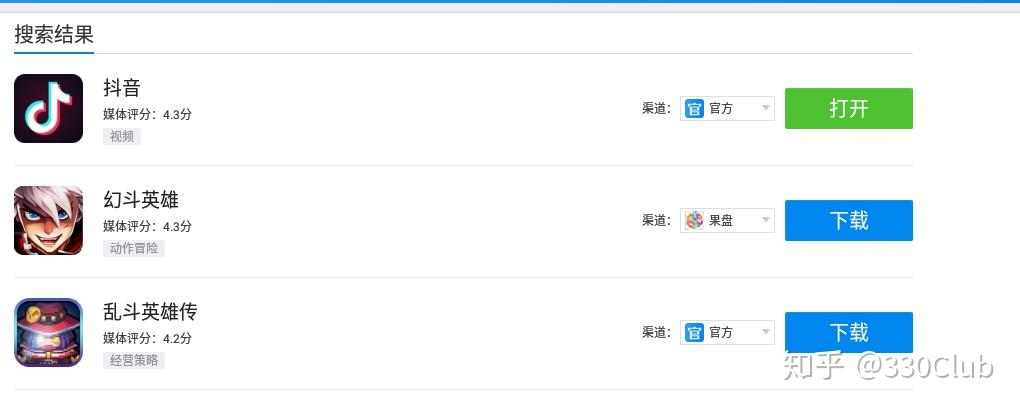
下载完在桌面上可以看到“抖音”
- 打开抖音
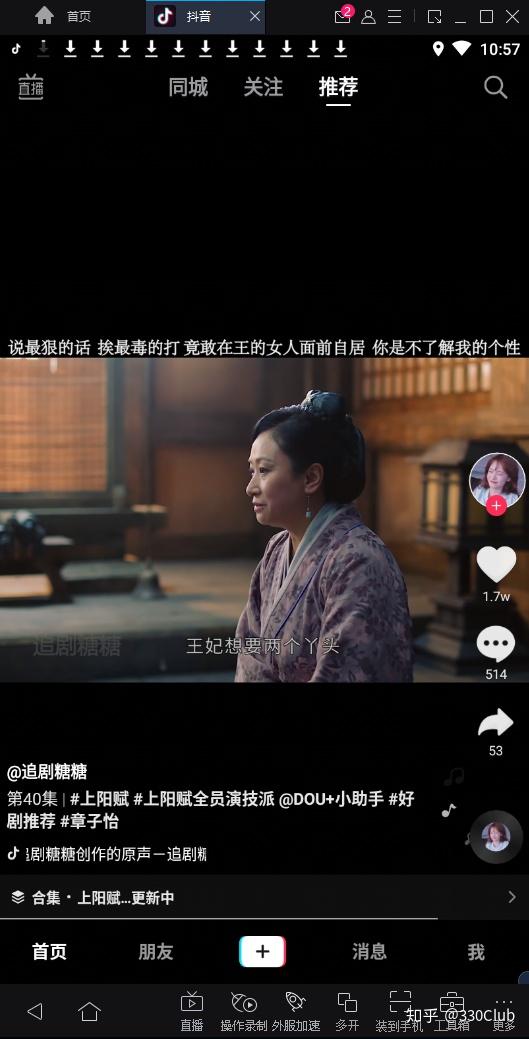
- 点击“直播”
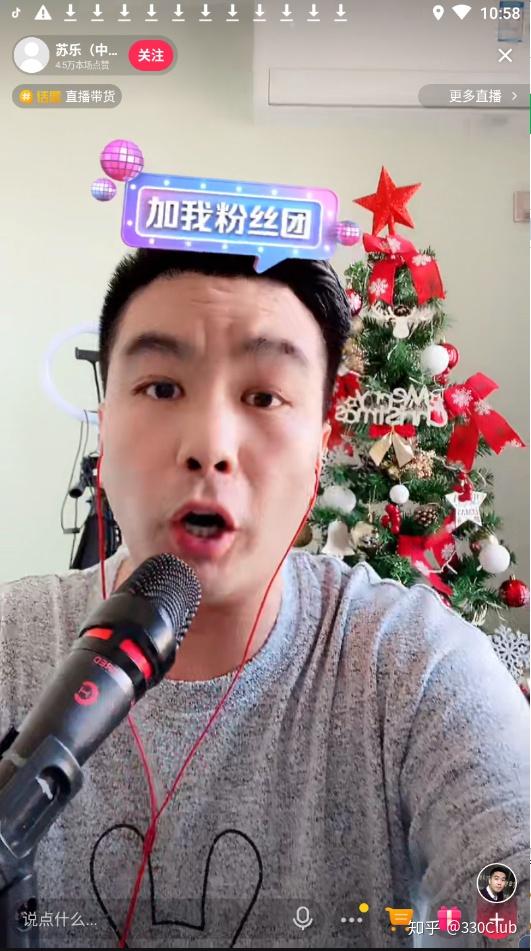
- 点击下面的三个点的按钮
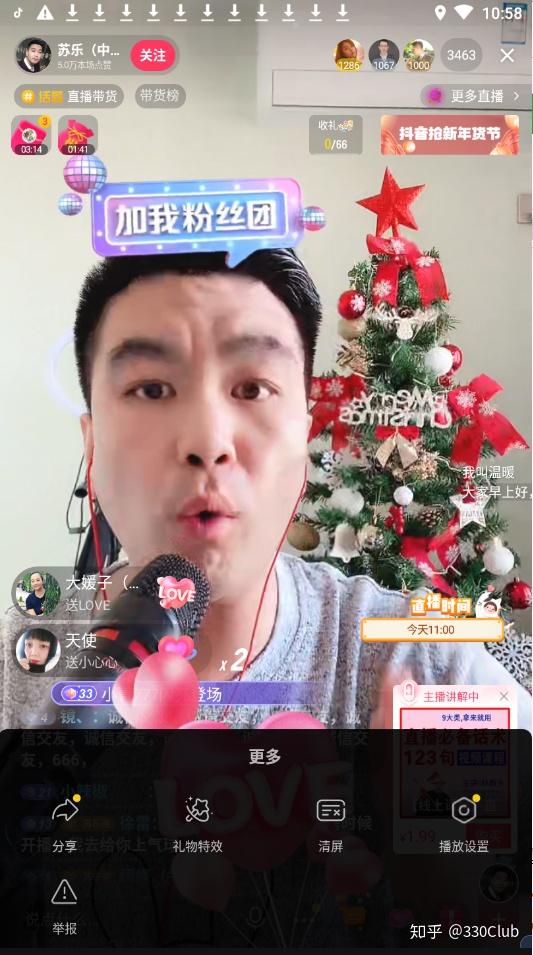
- 点击“分享”
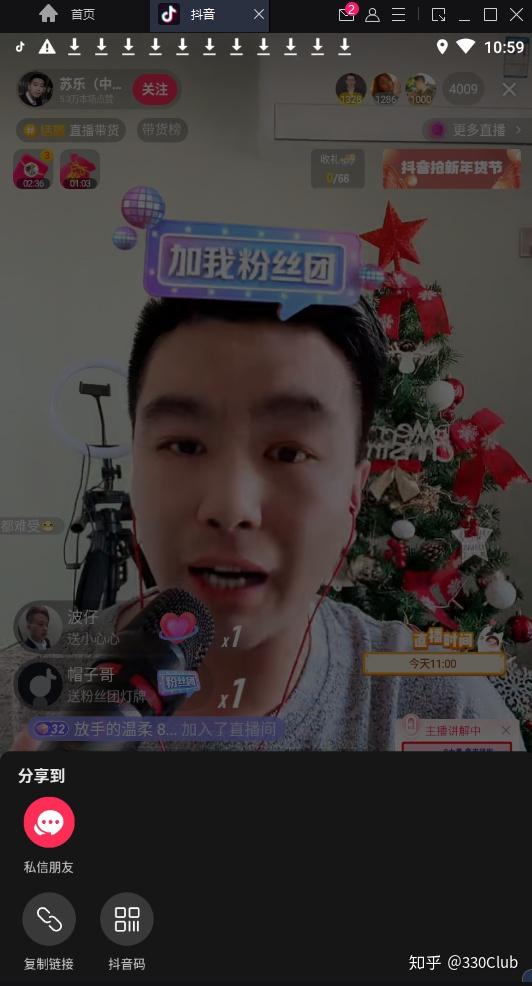
- 点击“复制链接”
在浏览器中粘贴刚才复制的网址“#在抖音,记录美好生活#【苏乐(中午11:00直播)】正在直播,来和我一起支持TA吧。复制下方链接,打开【抖音】,直接观看直播! https://v.douyin.com/Jn1H2uE/”,删除前面的文字,打开链接
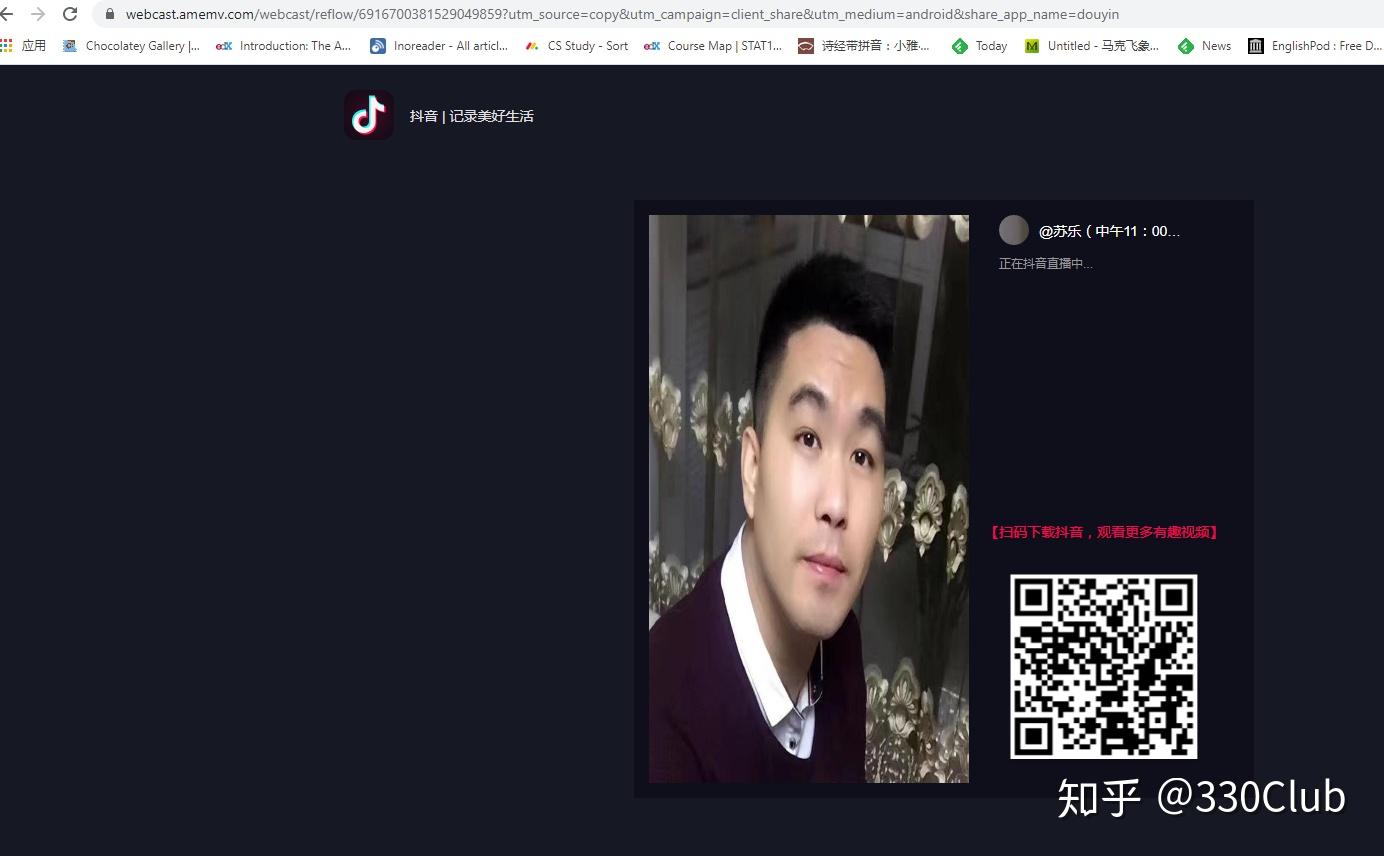
页面显示的就是抖音中的主播
这时候网址重定向了,变成“https://webcast.amemv.com/webcast/reflow/6916700381529049859?utm_source=copy&utm_campaign=client_share&utm_medium=android&share_app_name=douyin”
可以看到这个地址中有一串长数字,其他应该都是常量,不变的,复制这串长数字6916700381529049859,回到mitmproxy打开的地址,ctrl+F,搜索,如果搜不到,上下滑动页面,会看到很多地方都有这串数字
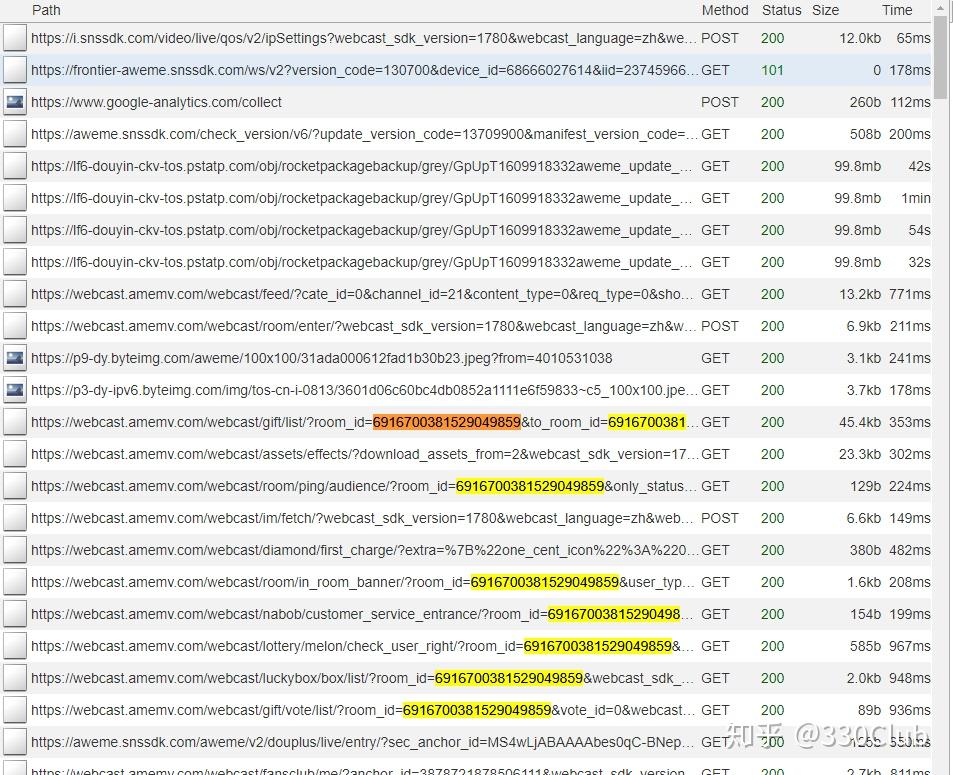
选中第一个,在右侧request会看到完整地址:

保留这个完整地址
再回到刚才打开的抖音分享页面,右键-》查看网页源代码
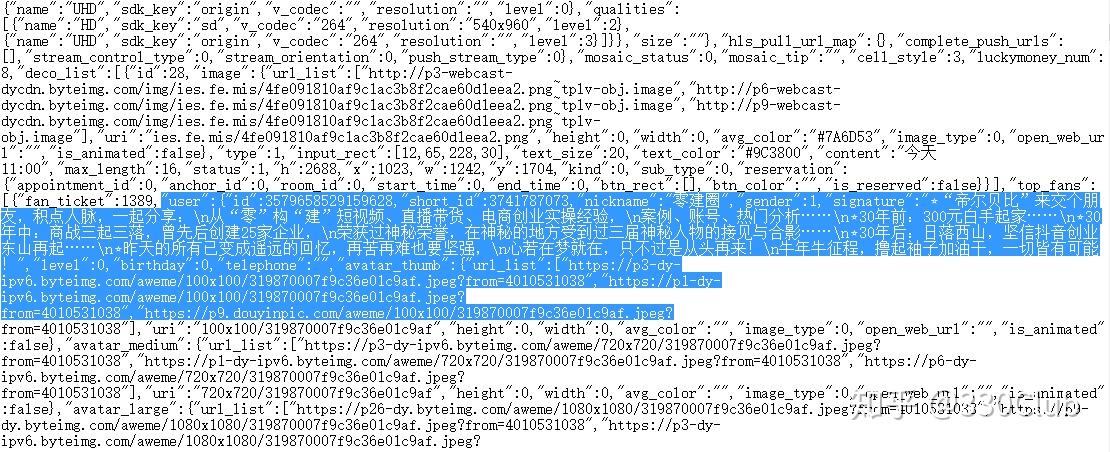
将源代码复制到其他编辑器里,我复制到记事本里
在记事本里,会发现一段script里包含了主播所有的信息,这就是我们要爬取的信息。
import urllib.parse as urlparse
from urllib.parse import parse_qs
def response(flow):
global idx
url_prefix = 'https://webcast.amemv.com/webcast/gift/list/'
if flow.request.pretty_url.startswith(url_prefix):
url = flow.request.pretty_url
save_room_id(url)
def save_room_id(url):
try:
parsed = urlparse.urlparse(url)
room_id = parse_qs(parsed.query)['room_id']
with open('rooms.txt', 'a') as f:
for data in room_id:
f.write(data)
f.write('\
')
except:
print('error')
这段脚本会获取抖音中主播的room_id,然后保存到一个txt文件中
在git中,先cd到脚本所在的文件夹,然后输入“mitmdump -s get_user.py -p 8888”
这时如果滑动抖音,就可以获取当前主播的room_id,并保存
现在用appium实现自动滑屏
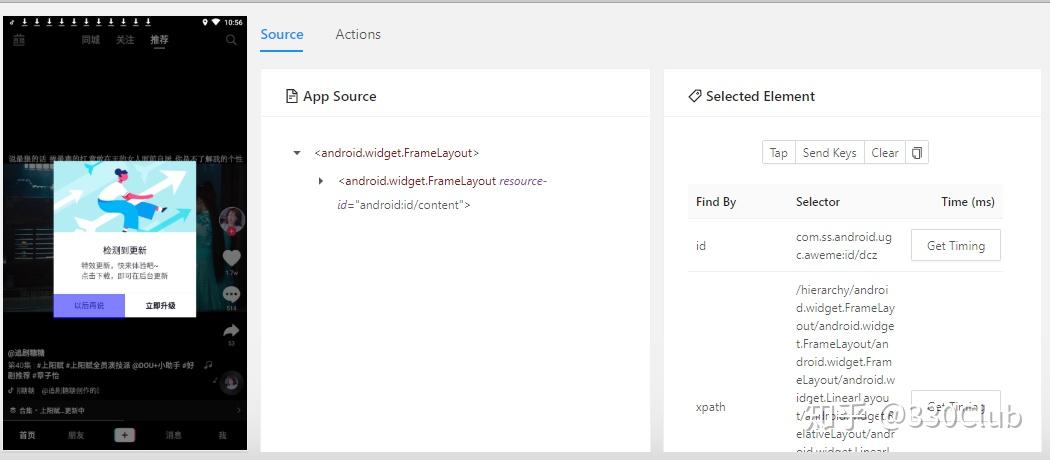
在appium中点击控件会在右侧显示控件id
抖音做了一些反爬虫设计,用appium打开抖音时,会出现一些授权窗口,我是出现了三个,所以需要先授权

授权完成之后,点击“直播”,然后每秒滑屏一次,代码如下
# -*- coding: utf-8 -*-
from appium import webdriver
from time import sleep
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
i=0
class DouYin(object):
def __init__(self):
# self.init_file()
self.desired_caps={
'platformName' : 'Android',
'platformVersion' : '6.0.1',
'deviceName' : '127.0.0.1:7555',
'appPackage' : 'com.ss.android.ugc.aweme',
'appActivity' : '.main.MainActivity'}
self.driver=webdriver.Remote('http://localhost:47233/wd/hub', self.desired_caps)
self.wait=WebDriverWait(self.driver, 60)
self.get_permission()
self.error_times=0
# self.init_file()
def swipe_up(self):
self.driver.swipe(373, 1029, 373, 387)
sleep(1)
# self.driver.tap([(385, 471)])
def zhibo(self):
self.driver.tap([(45, 80)], 500)
sleep(3)
def get_permission(self):
try:
allow=self.wait.until(
EC.presence_of_element_located((By.ID, 'com.ss.android.ugc.aweme:id/aps')))
if allow is not None:
allow.click()
allow=self.wait.until(
EC.presence_of_element_located((By.ID, 'com.android.packageinstaller:id/permission_deny_button')))
if allow is not None:
allow.click()
allow=self.wait.until(
EC.presence_of_element_located((By.ID, 'com.android.packageinstaller:id/permission_deny_button')))
if allow is not None:
allow.click()
sleep(10)
self.swipe_up()
self.zhibo()
except Exception as ex:
print(ex)
pass
def click_up(self):
ups_no=0
while True:
global i
try:
self.swipe_up()
i +=1
print(str(i))
except Exception as err:
print(err)
self.error_times +=1
if self.error_times < 5:
continue
else:
raise Exception('Error happens 5 times, restart')
def close_app(self):
self.driver.close_app()
def run(self):
self.click_up()
# self.close_app()
if __name__=='__main__':
while True:
try:
douyin=DouYin()
douyin.run()
except Exception as error:
print(error)这是自动爬取效果视频,我的电脑比较卡,实际滑屏时间要多于1秒
这段代码有几个小问题,还没解决
1. 抖音出现更新提示,运行一段时间会出现
2. 抖音运行一段时间会重启,重启后python仍然以为在直播,所以继续滑动,但是目前其实在推荐
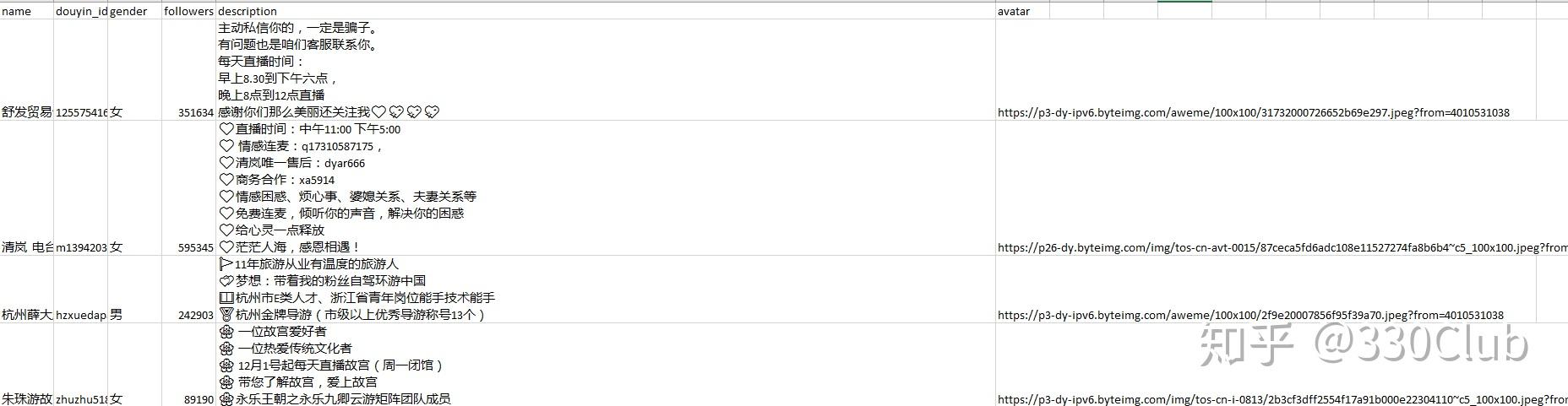
保存的主播room_id,可以用python脚本来获取主播详细信息并保存,这一步按需保存自己需要的信息,代码如下
import requests
import json
import csv
from bs4 import BeautifulSoup
import re
import os
csv_file='douyin.csv'
csv_columns=['name', 'douyin_id', 'gender','followers','description', 'avatar']
def save():
init_file()
with open('rooms.txt','r') as txt_file:
rooms=txt_file.read().split('\
')
for room in rooms:
save_one(room)
def save_one(room_id):
url='https://webcast.amemv.com/webcast/reflow/' + room_id + '?utm_source=copy&utm_campaign=client_share&utm_medium=android&share_app_name=douyin'
headers={
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36',
}
response=requests.get(url, headers=headers).text
soup=BeautifulSoup(response)
a=soup.find_all('script')
for t in a:
if 'owner_user_id' in str(t):
m=re.search('\\{.*\\}', str(t))
j=m.group(0)
j=json.loads(j)
user=j['/webcast/reflow/:id']['room']['owner']
save_ups(user)
user=json.dumps(user)
with open(f'user.json', 'a', encoding='utf-8-sig') as js:
js.write(user)
js.write('\
')
break
def init_file():
try:
if os.path.exists(csv_file):
return
with open(csv_file, 'w',encoding='utf-8-sig') as csvfile:
writer=csv.DictWriter(csvfile, fieldnames=csv_columns, delimiter=',', lineterminator='\
')
writer.writeheader()
except IOError as err:
print(err)
def save_ups(user):
up=dict()
up['name']=user['nickname']
up['douyin_id']=user['display_id']+'\ '
up['gender']='女' if user['gender']==2 else '男'
up['description']=user['signature']
up['followers']=user['follow_info']['follower_count']
up['avatar']=user['avatar_thumb']['url_list'][0]
with open(csv_file, 'a', encoding='utf-8-sig') as douyin:
writer=csv.DictWriter(douyin, fieldnames=csv_columns, delimiter=',', lineterminator='\
')
writer.writerow(up)这是爬取的数据: