
第一次写知乎文章, 在optimization里摸爬滚打了几年。 刚刚从学校刑满释放 。 最近受打击太多, 瞎写点东西, 跟各位大佬交流一下。 有错的地方请多指教。
先得感谢 @留德华叫兽 对整个学科科普做出的杰出贡献。(瞅瞅我崇拜的眼神, 能看出我迫切想抱大腿的期待不)? 作为一个离开东北13年的老男孩, 普及算法我下手晚了, 前边太多大佬领路。我整不好就只能推广推广东北话了!(不喜欢写文章。想到导师懂我, 做的几个项目也没硬要求我发表, 感恩)。 有幸被转载请注明出处, 并通知我下哈。
先盘腿上炕, 唠唠啥是优化问题 和 搜索问题:
优化问题, 就是在一个由约束定义的可行解域中根据优化方向寻找最优解的问题。
首先,这里讨论的优化问题一定是NP-hard问题 (对于NP-Complete, 这些主要是针对搜索问题的, i.e. 就是没有软约束 或者 没有目标函数的问题)。
举个例子, 大学课表排程问题(UCTP): c门课, l名老师, t个时间点 (Timeslots), s组学生(原本是Curriculum), r个教室。 多少总组合? 找到一个互相不冲突, 可以执行的组合就是一个搜索问题(NP-Hard)。如果说希望每学生的课可以尽可能的平均地分布在一周的时间里 , 就是优化问题 (NP-Complete, 最优解无法在多项式时间内被验证)。这里优化所有学生的课程间隔时长的标准差的和, 要尽可能最小。这就是最小化问题。
遇到一个优化问题, 就需要以下步骤来处理:
一,定义问题 :
- 确定Entities, Entities之间关系 (咋翻译?-实体 )
- 确定Hard Constraints 及 Soft Constraints (硬约束-决定节的可行性, 软约束-决定解的质量)
问题类型:
- 动态/静态优化问题(数据的准确度,及完整性)
- 单目标/多目标优化问题 (Decision Making/Supporting)
- 连续优化/整数优化
- 凸优化/凹优化
- 。。。。。。
二, 问题建模:(ILP)
- 定义决策变量
- 定义决策变量取值范围
- 定义目标函数/适应函数
- 转化约束函数
还有些使用CSP(Constraint Satisfaction Programming), ASP (Answer Set Programming)来建模的文章。 Prolog? Optimization? 有大佬有相关经验的欢迎指教。 我对这部分很好奇。
三,算法选型
需要根据问题的特点选择相应的算法类型。 主要分为精确优化算法及近似优化算法。需要参考一些问题的特点, 例如: 规模? 运算时间窗口( 动态/静态优化 )? 是否需要分布式计算等问题.
补充下, 在工界浑浑噩噩了快两年了, 认识到了一个严重的问题, 业界对算法的理解还普遍停留在规则的阶段。 也就是所谓的“贪婪算法” 或者叫’启发式构造算法‘。 不仅用来处理可行解的构造,也用来引入更加复杂的规则, 来对节进行优化。 用了很久去交流业界普遍对算法的认知,核心是两种思维模式的不同。业界认为:通过经验的积累, 可以不断深化规则, 得到更好的算法。 优化的理解是, ”请尊重数学, 把核心问题从粗暴的如何既能,又能。。。改为,如何找到冲突资源的合理分配,以平衡。。。。“, Nash, Respect!
四, 实施, 测试, 调参, 优化,再调参, 部署交付
这个以后再说, 或者欢迎大佬补充。
解决这问题可以全排不? DFS, BFS, DP行得通不? 答: 对于小规模问题,可以! 把问题用 整数线性规划问题(ILP)建模, 在用例如单纯形法,分支界定法等算法求解。 这类方法就是精确优化算法。通常使用Gurobi, CPlex 这些求解器来做(莫名想给杉数磕一个)。
再试想一下,如果有1000门课, 课跟老师之间是之间关系是一对多, 或者多对多呢? 如果5分钟出结果呢? 精确优化算法会说:实力不允许啊! 为啥? 因为问题规模 和运算时间的冲突!
问题规模主要由几方面体现(不全面, 欢迎补充):
- 问题维度
- 变量取值范围 (套用Constraints Satisfaction 的Term)
- 硬约束条件
- .etc.
面对问题规模太大的挑战怎么办? 用近似优化算法 !
近似优化算法。 这是一种 能在合理时间 内给出相对优秀解 的算法。
说人话, 就是在 运算时间 和求解效果 上互相取舍的产物。 (好的交易一定是双方都留有遗憾)。
通常来说, 精确优化算法是数学领域; 近似优化算法,是人工智能 (我家亲戚一直认为AI就是ML,DL, RL, 咋能给他们解释明白,求策略 )。
近似优化算法主要分为三种:
- 约束松弛方式;
- 一步优化方式;
- 二步优化方式。(敲黑板)
二步优化方式 (Two-Stage Approaches)
第一步, 使用启发式算法生成可行解 S0 (解决搜索问题, NP-Complete);
第二步,使用元启发式算法 从初始解(s0)开始,在可行解域内迭代探索新的区域,每一次迭代都根据上一次迭代的解 (s)生成一(批) 新的可行解(s'), 根据新解的优劣(由目标函数判定)指导下一次迭代生成新解的方向(搜索行为)。
有啥优点呢?
- 第一步生成可行解问题相对简单。 第二部对解有优化的能力。
- 一旦第一步完成, 第二步可以随时停止, 而且停止时一定能得到一个可行的近似最优解。
所以, 二步优化方式应用最为广泛!
回顾一下, 无论是启发式算法(Heuristic Algorithms), 元启发式算法(Meta-Heuristic Aglorightms) 或超启发式算法(Hyper-Heuristic Algorithm) 都是求解优化问题的近似优化算法。 都不能保证找到最优解。 相比后二者, 只有启发式算法是与问题强相关的。后二者, 都是相对问题独立的。(黑盒搜索)。
0x01: 启发算法,
打哪启发?答案是:人! 启发算法的启发来源, 就是人, 行业专家。
举个例子: 假如你是小偷(法外狂徒张三), 带了10个背包来我家, 每个包承重不一样,进门看到我家有1000件物品, 他们的都有各自的重量和价值。 你这10个背包肯定不能把我所有东西都带走。你咋选 ? 是不是先拿重量最小, 最值钱的,放在最小的包里。 小包装满了再装体积大的包。最后每个包都装不下新的物品了, 就跑去逍遥法外。 对! 这就是启发式算法。 但结果是最优的么? 不是。 还有缝隙。但你现在剩下的都是大件了。 添缝是不肯能的了。
同比,每一类问题, 需要特定的启发式算法。一维 背包有most fit,三维背包有 wall building, layer building, 排程问题有GCH, 最小图着色问题有RFL等等。
0x02: 元启发算法
咋就又"元“了, 哪”元“了啊? 元了问题! 元启发算法把问题的解 通过使用 ”适应函数“ 给表达成了数。不关注问题本身了, 儿只关注他的目标函数的值。 这样就具有了通用性。 回归到了优化行为本身, 所以就元了。 (这里不考虑算子设计这些哈, 也不考虑例如Guided Search这些哈)
首先, 作为二步优化方式的第二步, 他一定是一个迭代的算法。 这个迭代, 从第一步生成的初始解, 每次迭代, 都在可行解的范围内探索。 (部分算法为了最求收敛能力或者探索能力, 准许在某一阶段可以接受非可行解)。
这个新的解 可能比(当前/ 历史)最好的解更好/坏, 那这个解对下次迭代是否产生影响, 就是”Acceptance Criteria“。 例如Hill Climbing, 就只接受比当前解更好的解。 禁忌搜索TS, 接受当前解周围最好的解。 Harmony Search, 与种群中最差的解比较是否调换。 合理调整元启发算法的Acceptance Criteria, 可以平衡其搜索行为的exploration 及 exploitation。 也是元/超启发算法的核心问题。 借Talbi的话: 平衡这两个E, 不是Skill, 是Art。 当然, 有很多种其他方法来做平横。 其中包括通过引入学习机制提高适应性或做多种混合。对, 还有”调参“。
Termination Condition: 迭代什么时候停?
- 已经找到全局最优解 : 适应函数的值到达Lower Bound。
- 运算时间
- 迭代次数
- 未找到最优解的 运行时间/迭代次数
对于元启发算法, 大概就想到这, 以后会找机会扩展吧。
0x03: 超启发算法
定个意先:
超启发算法在元启发式算法基础上, 根据元启发式算法的搜索历史去学习, 从而调整元启发算法的行为模式。 做到“Learn to Search"。
对比一下:
启发式算法, 参考问题的解
元启发算法, 参考解的质量
超启发算法, 参考算法的行为 (”超“到了算法层面)
分类一下:
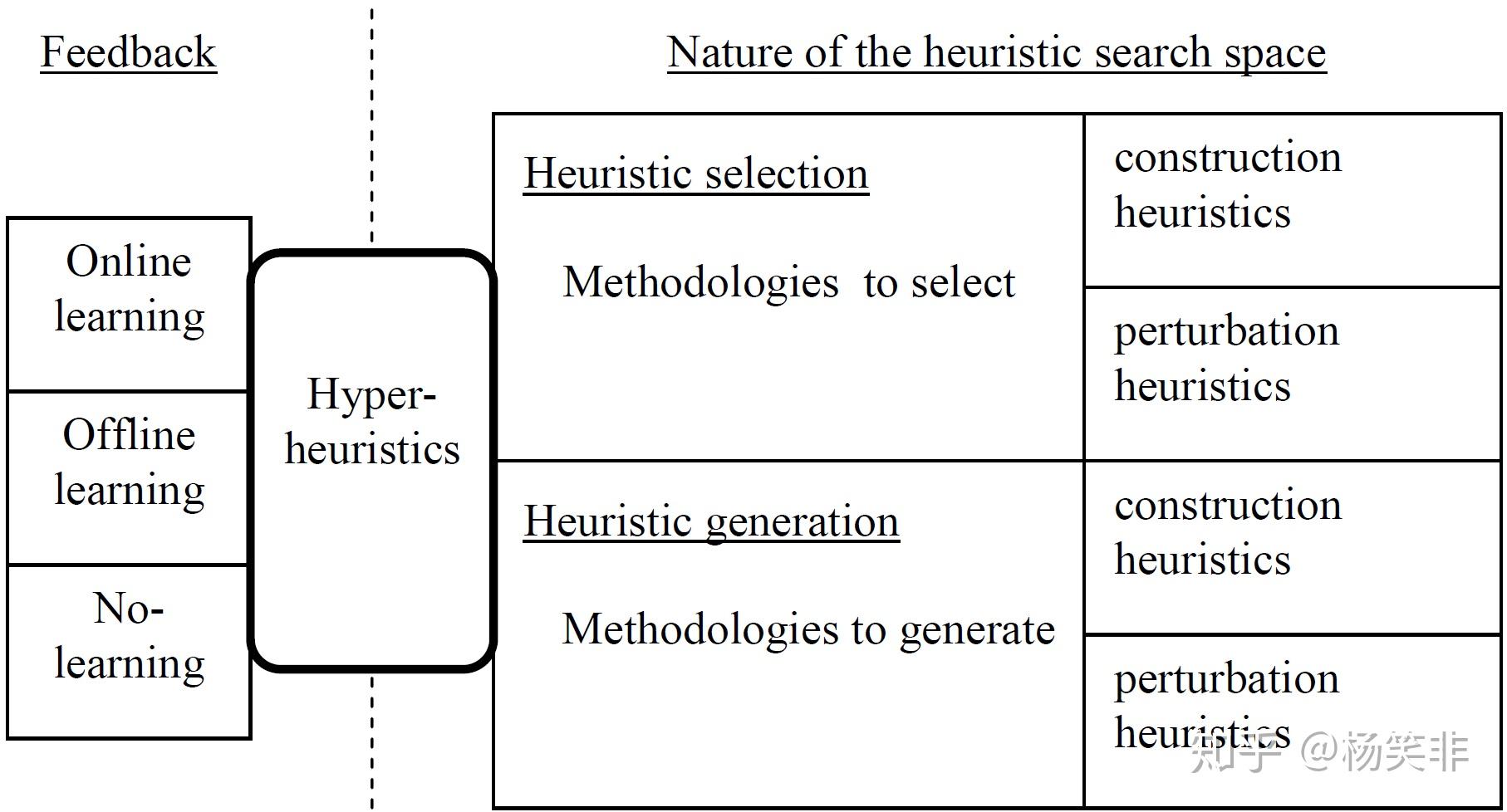
从学习方式分: Online, Offline, No-learning。
从对算法的控制: 算法选择, 算法生成。
对于超期发算法, 有一个基本的理念, 就是在整个优化的过程中,在合适的时间, 针对特定情况,使用合适的算法去完成优化搜索。
——————————————————总结---------------------------------------
作为第一篇知乎文章的第一版,以上的内容写了几个小时。写的全是大概(也不全), 没深入任何技术细节。 就是走一下, 算是个对今后短期内的文章缕一个框架。 如果客官您看着还行, 或者对哪个方向感兴趣,咱就多交流, 我就在下一篇展开。求鼓励。求交流,求相识。 求成长!。

